Code generation is a common tool in software. Usually it sits behind the scenes, just a layer of automation translating from one programming language to another. But sometimes it becomes useful to build your own code generator. In a project at work, we’ve implemented a code generator based off a DSL (domain specific language) that generates an implementation of our domain contract. There’s a lot of meaty terms in that last sentence, let’s spend some time and break them down.
Common use case: compilers
First, I said that code generation is common, but behind the scenes. That’s because most compilers have some form of code generation happening in them. So for example, compiling Typescript for a Web app, or compiling Swift for an iOS app.
Let’s talk a little more about compilers. A compiler’s job is to take source code that humans can read and produce output that a computer can run. This is broken up into parts:
- Parsing the source code
- Stuff
- Generate output.
Parsing the source code is all about understanding text and turning it into a format a computer can do stuff with.
Stuff could be interesting things, like in Typescript, adding static type checking to vanilla Javascript. This usually involves manipulating an abstract syntax tree. For example, you could enforce rules in the tree and make sure everything is valid.
Generate output is the code generation part. The tree needs to turn back into something that the computer can run. For Typescript this is generating Javascript, for Swift, this is producing machine code.
A quick example
2 + 2
Given the above syntax, parsing turns it into a syntax tree:
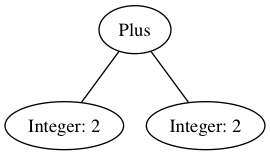
Then for stuff maybe we want to enforce that a “Plus” always has “integers” connected to it. In this case, our tree looks good.
For generate output, we need a rule for what to do with a “Plus”. I’m making up this rule:
- Load the left hand number into the computer.
- Load the right hand number into the computer.
- Add them.
So we apply that rule to our tree and get:
- Load a 2 into the computer.
- Load a 2 into the computer.
- Add them.
Which is approximately what machine language looks like 🙂 I linked to NAND to Tetris which my friend Devin Mork showed me. It reminds me of my computer architecture course in college.
Domain Specific Languages
A domain specific language is making your own programming language. This lets you (1) create a language that is more meaningful and specific, and (2) produce generated code that does something useful.
One example is defining an API between two microservices. You could exchange URL’s back and forth between developers:
https://example.com/api/add-numbers
https://example.com/api/get-result
But then you’d also need to agree on an API body format (maybe JSON), whether things are a GET or a POST, and a myriad of other details.
What if instead you could use a DSL that let you define the following:
api Math {
command add-numbers(
leftHand: int,
rightHand: int
);
query get-result(
);
}
This defines something meaningful to the domain (we have an api with a command and a query), but hides the implementation.
The implementation could be a Web API, it could be a “REST API,” it could be something like Apple’s XPC. This implementation would be built out as a set of code generators, but it is not part of the domain definition. So for example, we could generate a Jersey controller:
@Path("/Math")
public class MathController {
@GET
@Path("/get-result")
public Response getResult() {
//something
}
@POST
@Path("/add-numbers")
public Response addNumbers(@QueryParam("leftHand") String leftHand, @QueryParam("rightHand") String rightHand) {
//something
}
}
This is a partial example, you’d need a bridge between the generated code and hand-written code. For example, maybe “something” is a call to an interface that a developer will implement by hand.
This is not a new idea, Martin Fowler wrote a book “Domain Specific Languages.” For web APIs see also grpc and api blueprint. If those meet your needs, I would use those instead of making the investment in building your own DSL and code generator.
