When you upload an image to WordPress, it is stored in its original size on the web server. WordPress allows you to specify an image size. WordPress will create an additional copy of the image at that size and insert that in the page instead.
Here is an example:
Original size: 1858×1233 (652 kB)
Wordpress copy: 1024×679 (336 kB)
This means that when people view your page, they have to download 0.5 times the original file size. This is a smaller file download, and it will help your page load faster.
Point to remember: If you choose a size when you insert an image, it tells WordPress to create a smaller file download. This will help your page load faster.
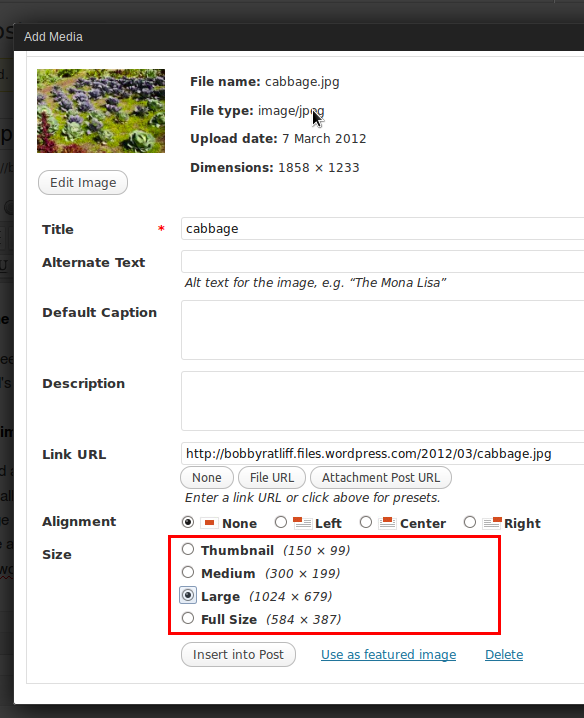
Resizing images
After inserting an image and viewing the page in a web browser, usually you’ll find that your image is too large. So then you go in the Edit Image window and set a smaller size, e.g. 70%:
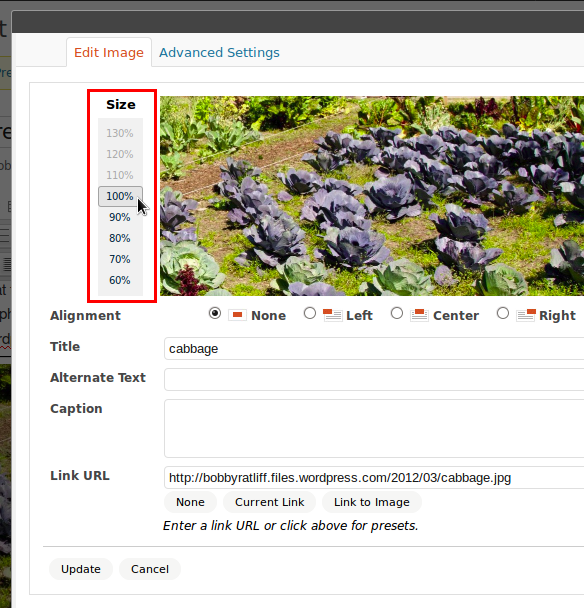
This presents a problem: If you use the Edit Image window, WordPress will not automatically resize your image file a second time. It will only display the image smaller. This means that the web browser is still downloading the full size file, but it is just viewing it smaller.
I tried resizing the cabbage image above to 70%. Here is what happened:
WordPress size: 1024×679 (336 kB) — Recall that this is due to our choice of size in the Insert Image box.
New size at 70%: 717×475 (336 kB) — But this image could be 186 kB if I resized the actual file.
See the difference? If you resize an image with the Insert Image box, it will actually save space, but if you resize an image with the Edit Image box, it will not actually save space.
Conclusion
Correctly scaling your images before inserting them into a post will solve this problem. If you are going to be inserting a lot of images, use a test image. Insert a single image and use the Edit Image box to find out what size looks right. Then on your computer, resize all your images to this size before inserting them into the post.
Misc notes
Another thing you have to take into account when viewing images is the maximum width of the content in your theme. For example, this blog (bobbyratliff.wordpress.com) uses the Twenty Eleven theme, where the maximum width is 585. Even if I choose the 1024×769 option, the image width is limited to 585. In other words, it will show the cabbage image as 570×377.
Another solution is to add image sizes to the insert image dialog. If you have hosted WordPress, you can use the Additional image sizes plugin to do it.
Google Page Speed is a great tool for troubleshooting slow sites. It has a list of rules that it evaluates your website against. When your page breaks a rule, it will tell you why and give some clues on how to fix it. The information in this post applies to the suggestion “Serve scaled images.”
 is related to the shift to the left
is related to the shift to the left  by the following equation:
by the following equation:
 is the radius of the wheel.
is the radius of the wheel.